前言
对于刚接触ByteBuffer人来说,想要完全理解会稍微有点困难,正巧前几天有人问我,想到好久没写文章,就整理一下。
概念理解
对于ByteBuffer的一些概念不理解的情况下,如果直接打开源码,硬啃,是一种方法,但是对于有些耐心不足的同学,恐怕坚持不下去。
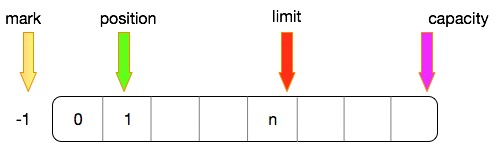
第一点,ByteBuffer底层的存储结构就是数组,所有的操作都是基于数组的操作。数组有哪几个重要的属性呢?元素索引和数组长度。

上面的图就简单的理解为一个数组。
既然ByteBuffer的存储结构为一个数组,那么就离不开索引位置和数组长度的概念。
mark(标记位)
position(当前位置)
limit(限定位置)
capacity(容量)
这四个概念是ByteBuffer数据操作的核心概念,只要把这四个的关系理清楚,那么在使用ByteBuffer的时候基本不会出现问题
基本读写状态
初始化状态
在初始的时候,这四个的相对位置,如下
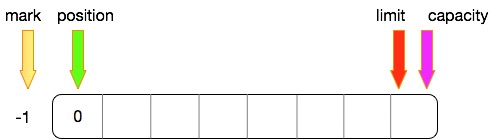
- mark:默认为-1,即没有做任何的标记
- position:当前位置为0
- limit和capacity:默认这两个相同
写状态
在向ByteBuffer写入一个字节(put操作)的时候,相对位置如下
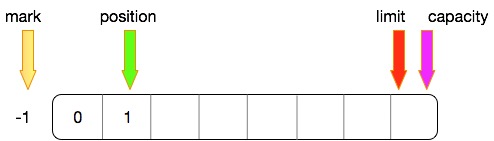
- mark:没有任何移动
- position:写入一个字节,position++
- limit和capacity:依然指向最后
写转读状态
在写入n个字节之后,位置如下
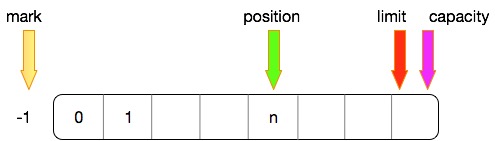
此时调用flip操作,由写模式转为读模式,位置变化过程如下:
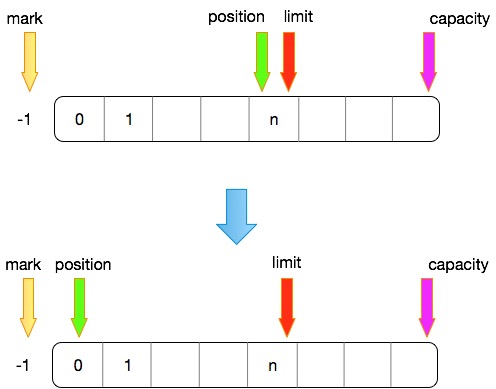
- 写转读的时候,会先把limit指向position的位置,即在读模式下,limit表示可以读取多少个字节,其余(limit到capacity之间的)的是不可读的
- position强制赋值为0,意味着可以从0索引处开始读取
- 【NOTE】 mark操作在上图没有体现,但是即使mark位置不在-1处,这里也会强制将mark设置为-1
读状态
通过get操作进行读取时,位置如下
读取一个字节时,位置变化
- mark:位置不变
- position:向前移动一个位置
- limit:位置不变,为读取上限,limit之后的内容不可读
- capacity:位置不变,依然指向最后
操作状态
通过上面的基本读写操作,四个的相对位置变化规律已经可以基本理解ByteBuffer的读写操作是如何实现的了,下面再说一下具体的一些操作
读操作
读操作提供了三个方法
- get() 相对读取,即读取当前position位置字节,读完之后position++
- get(int index) 绝对读取,即读取index位置的字节,此时会对index进行检查,看index是否超过limit的限制,如果超过抛出
IndexOutOfBoundsException;注意这时没有任何的位置移动- get(byte[] dst, int offset, int length)
- dst 数据读入的地方,就是将字节从ByteBuffer中读到dst
- offset 这个offset为dst的偏移量,不是ByteBuffer里面的offset(ByteBuffer里面也有一个offset,这里先忽略),即数据读到dst的时候,从offset的位置开始存储
- length 是要从ByteBuffer中读取多长的字节,即从position(当前)位置开始,读取length个字节到dst
- 这时,position的位置会加上length的长度;如果mark的位置比position大,那么将mark设置为-1
写操作
写操作提供了四个方法
- put(byte b) 相对写入,向position的位置写入一个字节,position++
- put(int index, byte b) 绝对写入,向索引为index的位置写入数据b,没有任何的位置移动
- put(ByteBuffer src) 相对写
- 这个首先要知道,这个操作是将src中的内容写入到调用的这个ByteBuffer中去,可能有人容易混淆
- 这里并不是将src所有的数据写入,而是讲src中可读的部分(即src中position到limit的部分)写入
- 这个src不是是调用者自身,否则会报错
- 如果src可读部分的长度大于了该ByteBuffer的剩余的长度,抛出
BufferOverflowException- 将src读出来的同时,也会变好src的position
- 将此ByteBuffer的position加上src可读部分的长度
- 这时,position的位置会加上length的长度;如果mark的位置比position大,那么将mark设置为-1
- put(byte[] src, int offset, int length)
- src 要写入的字节数组
- offset 这个offset也是src的offset,即从src的offset的位置开始
- length 这个length是要读取src的长度,即从src的offset的位置开始读取,读取length长度的字节到ByteBuffer中,此时position会加length
标记操作
标记操作,就一个公共方法mark()
- mark() 将mark的位置设置为position的位置,如果position比mark小,mark会被设置为-1
重置到标记操作
- reset() 把position设置为mark的位置,回到之前做标记的地方,如果mark小于0,抛异常InvalidMarkException
重置到初始操作
- rewind() 与reset类似,是将状态重置,但是reset只能重置到mark标记过的位置,而rewind是将mark=-1,position设置为0
清除操作
- clear() 不知道叫清除操作是否合适,这里clear的并不是数组里面的数据,而是将这四个的位置恢复初始化的状态。position=0,mark=-1,limit=capacity。此时ByteBuffer数组中的内容依然存在,但是数据的准确性并无法保证。所以在调用clear方法的时候,一定要清楚的知道自己的操作是否合理
写转读操作
- flip() 该操作在上面已经介绍过了
限制操作
提供了两个方法,limit()和limit(int newLimit)
- limit() 该操作其实没有实际操作,就是获取当前limit的位置
- limit(newLimit) 该操作是重新设置一个limit的操作,如果比capacity大,那么异常,如果newLimit比position小,那么position会设置为newLimit的位置
获取未读容量操作
- remaining() 获取剩余可读容量,即limit - position
- hasRemaining() 返回是否有未读内容
压缩整理操作
- compact() 将还没有读取的内容移动到开头的位置,即把position到limit的内容移动到从0开始,然后把position设置为未读内容长度的位置,limit设置为capacity的位置
实例化
ByteBuffer的基本操作基本已经介绍完了,那么ByteBuffer如何初始化呢?
从源码可以看出来ByteBuffer是一个抽象类,所以,不能被实例化。但是提供了四个静态方法
allocate(int capacity)
在堆上分配一个容量为capacity的数组作为存储容器
1 | ByteBuffer byteBuffer = ByteBuffer.allocate(1024); |
allocateDirect(int capacity)
不是在虚拟机堆上创建,而是分配的操作系统的直接内存,这样能更进一步提升io的性能,但是,分配直接内存的开销很大,所以只有在缓冲区需要长时间存在的情况下,使用这种初始化方式会更加优秀
1 | ByteBuffer byteBuffer = ByteBuffer.allocateDirect(1024); |
wrap(byte[] array)
相当于allocate操作,只不过,allocate是在ByteBuffer内容创建了一个字节数组用于存储数据,而wrap(byte[] array) 是在ByteBuffer外面创建了一个字节数组,用于存储存储数据,无论是直接操作array亦或是操作ByteBuffer都会更改存储值
wrap(byte[] array, int offset, int length)
在wrap(byte[] array) 的基础上指定offset和length。offset就是position,length读取的长度
其他
除了ByteBuffer之外,还提供了除Boolean之外的其他缓存类,使用方法基本相同
